
Research profile
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Clausthal University of TechnologyPhD CandidateFeb. 2025 - present
Clausthal University of TechnologyPhD CandidateFeb. 2025 - present -
 University of MannheimPhD CandidateSept. 2023 - Jan. 2025
University of MannheimPhD CandidateSept. 2023 - Jan. 2025 -
University of MannheimM.Sc. in Information ScienceJan. 2021 - Aug. 2023
-
 Lappeenranta University of Technology, FinlandSemester AbroadJan. 2020 - Apr. 2020
Lappeenranta University of Technology, FinlandSemester AbroadJan. 2020 - Apr. 2020 -
University of MannheimB.Sc. in Information ScienceSep. 2017 - Dec. 2020
Experience
-
 Ramblr GmbH, MunichPhD InternshipSept. 2025 - Nov. 2025
Ramblr GmbH, MunichPhD InternshipSept. 2025 - Nov. 2025 -
 Robert-Bosch GmbH, BühlMasterandOct. 2022 - Apr. 2023
Robert-Bosch GmbH, BühlMasterandOct. 2022 - Apr. 2023 -
Robert-Bosch GmbH, BühlWorking StudentJul. 2022 - Aug. 2023
-
 Institute for Enterprise Systems, MannheimScientific AssistantJan. 2022 - Aug. 2023
Institute for Enterprise Systems, MannheimScientific AssistantJan. 2022 - Aug. 2023 -
 Grosse-Hornke, MünsterWorking StudentNov. 2021 - Jul. 2022
Grosse-Hornke, MünsterWorking StudentNov. 2021 - Jul. 2022 -
Robert-Bosch GmbH, BühlWorking StudentJan. 2021 - Dec. 2021
-
Robert-Bosch GmbH, BühlBachelorandSep. 2020 - Dec. 2020
-
Robert-Bosch GmbH, BühlInternMay 2020 - Aug. 2020
-
 Porsche AG, WeissachWorking StudentOct. 2019 - Dec. 2019
Porsche AG, WeissachWorking StudentOct. 2019 - Dec. 2019 -
Robert-Bosch GmbH, BühlInternJul. 2019 - Aug. 2019
Honors & Awards
-
Best Paper Award, 2nd Workshop on Compositional Learning (ComPLearn) @ ICML2026
-
Ideenwettbewerb Regionalpreis Mainz2025
News
Older news
Selected Publications (view all )

BARISTA: A Multi-Task Egocentric Benchmark for Compositional Visual Understanding
Patrick Knab*, Orgest Xhelili*, Inis Buzi, Drago Andres Guggiana Nilo, Mohd Saquib Khan, Lorenz Kolb, Manuel Scherzer, Kerem Yildirir, Christian Bartelt, Philipp Johannes Schubert (* equal contribution)
ICML 2026 Workshop on Combining Theory and Benchmarks: Towards a Virtuous Cycle to Understand and Guarantee Foundation Model Performance (CTB) 2026
Scene understanding is central to general physical intelligence, and video is a primary modality for capturing both state and temporal dynamics of a scene. Yet understanding physical processes remains difficult, as models must combine object localization, hand-object interactions, relational parsing, temporal reasoning, and step-level procedural inference. Existing benchmarks usually evaluate these capabilities separately, limiting diagnosis of why models fail on procedural tasks. We introduce BARISTA, a densely annotated egocentric dataset and benchmark of 185 real-world coffee-preparation videos covering fully automatic, portafilter-based, and capsule-based workflows. BARISTA provides verified per-frame scene graphs linking persistent object identities to masks, tracks, boxes, attributes, typed relations, hand-object interactions, activities, and process steps. From these graphs, we derive zero-shot language-based tasks spanning phrase grounding, hand-object interaction recognition, referring, activity recognition, relation extraction, and temporal visual question answering. Experiments reveal strong variation across task families and no consistently dominant model family, positioning BARISTA as a challenging diagnostic benchmark for procedural video understanding.
BARISTA: A Multi-Task Egocentric Benchmark for Compositional Visual Understanding
Patrick Knab*, Orgest Xhelili*, Inis Buzi, Drago Andres Guggiana Nilo, Mohd Saquib Khan, Lorenz Kolb, Manuel Scherzer, Kerem Yildirir, Christian Bartelt, Philipp Johannes Schubert (* equal contribution)
ICML 2026 Workshop on Combining Theory and Benchmarks: Towards a Virtuous Cycle to Understand and Guarantee Foundation Model Performance (CTB) 2026
Abstract
Scene understanding is central to general physical intelligence, and video is a primary modality for capturing both state and temporal dynamics of a scene. Yet understanding physical processes remains difficult, as models must combine object localization, hand-object interactions, relational parsing, temporal reasoning, and step-level procedural inference. Existing benchmarks usually evaluate these capabilities separately, limiting diagnosis of why models fail on procedural tasks. We introduce BARISTA, a densely annotated egocentric dataset and benchmark of 185 real-world coffee-preparation videos covering fully automatic, portafilter-based, and capsule-based workflows. BARISTA provides verified per-frame scene graphs linking persistent object identities to masks, tracks, boxes, attributes, typed relations, hand-object interactions, activities, and process steps. From these graphs, we derive zero-shot language-based tasks spanning phrase grounding, hand-object interaction recognition, referring, activity recognition, relation extraction, and temporal visual question answering. Experiments reveal strong variation across task families and no consistently dominant model family, positioning BARISTA as a challenging diagnostic benchmark for procedural video understanding.
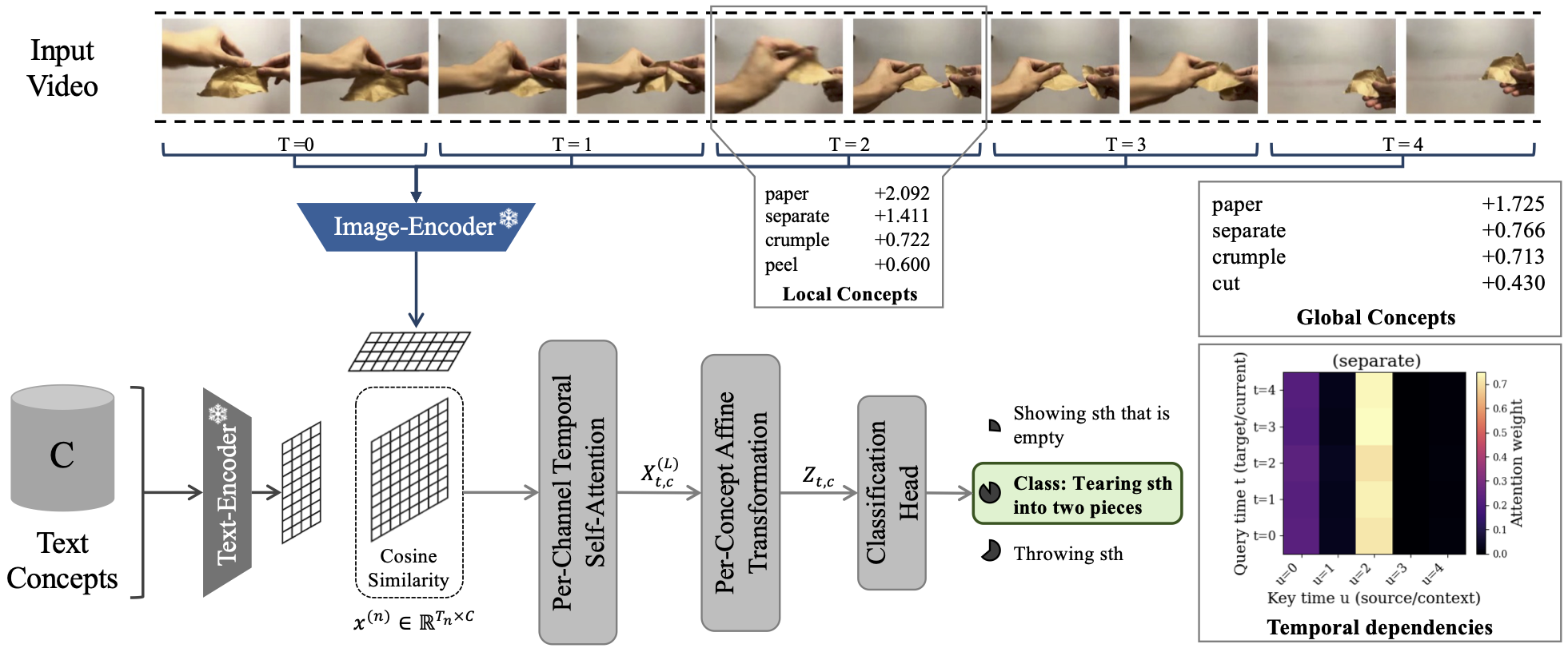
Concepts in Motion: Temporal Bottlenecks for Interpretable Video Classification
Patrick Knab, Sascha Marton, Philipp J Schubert, Drago Guggiana, Christian Bartelt
2nd Workshop on Compositional Learning (ComPLearn) @ International Conference on Machine Learning (ICML) (Spotlight, Best Paper Award) 2026
Conceptual models such as Concept Bottleneck Models (CBMs) have driven substantial progress in improving interpretability for image classification by leveraging human-interpretable concepts. However, extending these models from static images to sequences of images, such as video data, introduces a significant challenge due to the temporal dependencies inherent in videos, which are essential for capturing actions and events. In this work, we introduce MoTIF (Moving Temporal Interpretable Framework), an architectural design inspired by a transformer that adapts the concept bottleneck framework for video classification and handles sequences of arbitrary length. Within the video domain, concepts refer to semantic entities such as objects, attributes, or higher-level components (e.g., 'bow', 'mount', 'shoot') that reoccur across time - forming motifs collectively describing and explaining actions. Our design explicitly enables three complementary perspectives: global concept importance across the entire video, local concept relevance within specific windows, and temporal dependencies of a concept over time. Our results demonstrate that the concept-based modeling paradigm can be effectively transferred to video data, enabling a better understanding of concept contributions in temporal contexts while maintaining competitive performance. Code available at github.com/patrick-knab/MoTIF.
Concepts in Motion: Temporal Bottlenecks for Interpretable Video Classification
Patrick Knab, Sascha Marton, Philipp J Schubert, Drago Guggiana, Christian Bartelt
2nd Workshop on Compositional Learning (ComPLearn) @ International Conference on Machine Learning (ICML) (Spotlight, Best Paper Award) 2026
Abstract
Conceptual models such as Concept Bottleneck Models (CBMs) have driven substantial progress in improving interpretability for image classification by leveraging human-interpretable concepts. However, extending these models from static images to sequences of images, such as video data, introduces a significant challenge due to the temporal dependencies inherent in videos, which are essential for capturing actions and events. In this work, we introduce MoTIF (Moving Temporal Interpretable Framework), an architectural design inspired by a transformer that adapts the concept bottleneck framework for video classification and handles sequences of arbitrary length. Within the video domain, concepts refer to semantic entities such as objects, attributes, or higher-level components (e.g., 'bow', 'mount', 'shoot') that reoccur across time - forming motifs collectively describing and explaining actions. Our design explicitly enables three complementary perspectives: global concept importance across the entire video, local concept relevance within specific windows, and temporal dependencies of a concept over time. Our results demonstrate that the concept-based modeling paradigm can be effectively transferred to video data, enabling a better understanding of concept contributions in temporal contexts while maintaining competitive performance. Code available at github.com/patrick-knab/MoTIF.
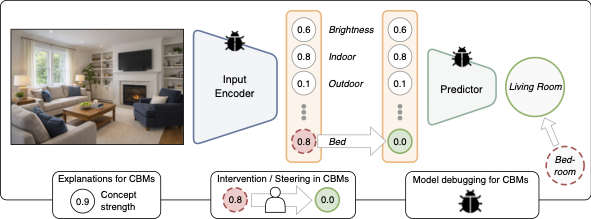
What's in the Bottle? A Survey and Roadmap of Concept Bottleneck Models
Patrick Knab*, David Steinmann*, Christian Bartelt, Kristian Kersting, Bernt Schiele, Thomas Seidl, Udo Schlegel†, Wolfgang Stammer† (* equal contribution, † equal supervision)
Transactions on Machine Learning Research (TMLR) 2026
Concept Bottleneck Models (CBMs) are interpretable learning architectures that factor predictions through intermediate, ideally human-understandable concepts, enabling explicit and inspectable reasoning. Although CBM research has gained substantial momentum in recent years, this growth has also revealed numerous open challenges and a fragmented set of methodological choices. In this work, we systematically review the CBM literature, identify previously unidentified core components and challenges, and propose a unified taxonomy. Based on this taxonomy, we provide a detailed categorization of existing works. We hereby discuss current challenges for the CBM paradigm and outline important directions to extend it beyond its current scope. Overall, this survey aims to consolidate the CBM landscape, clarify open issues, and provide guidance for developing future models.
What's in the Bottle? A Survey and Roadmap of Concept Bottleneck Models
Patrick Knab*, David Steinmann*, Christian Bartelt, Kristian Kersting, Bernt Schiele, Thomas Seidl, Udo Schlegel†, Wolfgang Stammer† (* equal contribution, † equal supervision)
Transactions on Machine Learning Research (TMLR) 2026
Abstract
Concept Bottleneck Models (CBMs) are interpretable learning architectures that factor predictions through intermediate, ideally human-understandable concepts, enabling explicit and inspectable reasoning. Although CBM research has gained substantial momentum in recent years, this growth has also revealed numerous open challenges and a fragmented set of methodological choices. In this work, we systematically review the CBM literature, identify previously unidentified core components and challenges, and propose a unified taxonomy. Based on this taxonomy, we provide a detailed categorization of existing works. We hereby discuss current challenges for the CBM paradigm and outline important directions to extend it beyond its current scope. Overall, this survey aims to consolidate the CBM landscape, clarify open issues, and provide guidance for developing future models.
BARISTA: A Multi-Task Egocentric Benchmark for Compositional Visual Understanding
Patrick Knab*, Orgest Xhelili*, Inis Buzi, Drago Andres Guggiana Nilo, Mohd Saquib Khan, Lorenz Kolb, Manuel Scherzer, Kerem Yildirir, Christian Bartelt, Philipp Johannes Schubert (* equal contribution)
Preprint 2026
Scene understanding is central to general physical intelligence, and video is a primary modality for capturing both state and temporal dynamics of a scene. Yet understanding physical processes remains difficult, as models must combine object localization, hand-object interactions, relational parsing, temporal reasoning, and step-level procedural inference. Existing benchmarks usually evaluate these capabilities separately, limiting diagnosis of why models fail on procedural tasks. We introduce BARISTA, a densely annotated egocentric dataset and benchmark of 185 real-world coffee-preparation videos covering fully automatic, portafilter-based, and capsule-based workflows. BARISTA provides verified per-frame scene graphs linking persistent object identities to masks, tracks, boxes, attributes, typed relations, hand-object interactions, activities, and process steps. From these graphs, we derive zero-shot language-based tasks spanning phrase grounding, hand-object interaction recognition, referring, activity recognition, relation extraction, and temporal visual question answering. Experiments reveal strong variation across task families and no consistently dominant model family, positioning BARISTA as a challenging diagnostic benchmark for procedural video understanding.
BARISTA: A Multi-Task Egocentric Benchmark for Compositional Visual Understanding
Patrick Knab*, Orgest Xhelili*, Inis Buzi, Drago Andres Guggiana Nilo, Mohd Saquib Khan, Lorenz Kolb, Manuel Scherzer, Kerem Yildirir, Christian Bartelt, Philipp Johannes Schubert (* equal contribution)
Preprint 2026
Abstract
Scene understanding is central to general physical intelligence, and video is a primary modality for capturing both state and temporal dynamics of a scene. Yet understanding physical processes remains difficult, as models must combine object localization, hand-object interactions, relational parsing, temporal reasoning, and step-level procedural inference. Existing benchmarks usually evaluate these capabilities separately, limiting diagnosis of why models fail on procedural tasks. We introduce BARISTA, a densely annotated egocentric dataset and benchmark of 185 real-world coffee-preparation videos covering fully automatic, portafilter-based, and capsule-based workflows. BARISTA provides verified per-frame scene graphs linking persistent object identities to masks, tracks, boxes, attributes, typed relations, hand-object interactions, activities, and process steps. From these graphs, we derive zero-shot language-based tasks spanning phrase grounding, hand-object interaction recognition, referring, activity recognition, relation extraction, and temporal visual question answering. Experiments reveal strong variation across task families and no consistently dominant model family, positioning BARISTA as a challenging diagnostic benchmark for procedural video understanding.
Concepts in Motion: Temporal Bottlenecks for Interpretable Video Classification
Patrick Knab, Sascha Marton, Philipp J Schubert, Drago Guggiana, Christian Bartelt
Conference on Computer Vision and Pattern Recognition (CVPR) @ XAI4CV Workshop (Spotlight) 2026
Conceptual models such as Concept Bottleneck Models (CBMs) have driven substantial progress in improving interpretability for image classification by leveraging human-interpretable concepts. However, extending these models from static images to sequences of images, such as video data, introduces a significant challenge due to the temporal dependencies inherent in videos, which are essential for capturing actions and events. In this work, we introduce MoTIF (Moving Temporal Interpretable Framework), an architectural design inspired by a transformer that adapts the concept bottleneck framework for video classification and handles sequences of arbitrary length. Within the video domain, concepts refer to semantic entities such as objects, attributes, or higher-level components (e.g., 'bow', 'mount', 'shoot') that reoccur across time - forming motifs collectively describing and explaining actions. Our design explicitly enables three complementary perspectives: global concept importance across the entire video, local concept relevance within specific windows, and temporal dependencies of a concept over time. Our results demonstrate that the concept-based modeling paradigm can be effectively transferred to video data, enabling a better understanding of concept contributions in temporal contexts while maintaining competitive performance. Code available at github.com/patrick-knab/MoTIF.
Concepts in Motion: Temporal Bottlenecks for Interpretable Video Classification
Patrick Knab, Sascha Marton, Philipp J Schubert, Drago Guggiana, Christian Bartelt
Conference on Computer Vision and Pattern Recognition (CVPR) @ XAI4CV Workshop (Spotlight) 2026
Abstract
Conceptual models such as Concept Bottleneck Models (CBMs) have driven substantial progress in improving interpretability for image classification by leveraging human-interpretable concepts. However, extending these models from static images to sequences of images, such as video data, introduces a significant challenge due to the temporal dependencies inherent in videos, which are essential for capturing actions and events. In this work, we introduce MoTIF (Moving Temporal Interpretable Framework), an architectural design inspired by a transformer that adapts the concept bottleneck framework for video classification and handles sequences of arbitrary length. Within the video domain, concepts refer to semantic entities such as objects, attributes, or higher-level components (e.g., 'bow', 'mount', 'shoot') that reoccur across time - forming motifs collectively describing and explaining actions. Our design explicitly enables three complementary perspectives: global concept importance across the entire video, local concept relevance within specific windows, and temporal dependencies of a concept over time. Our results demonstrate that the concept-based modeling paradigm can be effectively transferred to video data, enabling a better understanding of concept contributions in temporal contexts while maintaining competitive performance. Code available at github.com/patrick-knab/MoTIF.
What's in the Bottle? A Survey and Roadmap of Concept Bottleneck Models
Patrick Knab*, David Steinmann*, Christian Bartelt, Kristian Kersting, Bernt Schiele, Thomas Seidl, Udo Schlegel†, Wolfgang Stammer† (* equal contribution, † equal supervision)
Preprint 2026
Concept Bottleneck Models (CBMs) are interpretable learning architectures that factor predictions through intermediate, ideally human-understandable concepts, enabling explicit and inspectable reasoning. Although CBM research has gained substantial momentum in recent years, this growth has also revealed numerous open challenges and a fragmented set of methodological choices. In this work, we systematically review the CBM literature, identify previously unidentified core components and challenges, and propose a unified taxonomy. Based on this taxonomy, we provide a detailed categorization of existing works. We hereby discuss current challenges for the CBM paradigm and outline important directions to extend it beyond its current scope. Overall, this survey aims to consolidate the CBM landscape, clarify open issues, and provide guidance for developing future models.
What's in the Bottle? A Survey and Roadmap of Concept Bottleneck Models
Patrick Knab*, David Steinmann*, Christian Bartelt, Kristian Kersting, Bernt Schiele, Thomas Seidl, Udo Schlegel†, Wolfgang Stammer† (* equal contribution, † equal supervision)
Preprint 2026
Abstract
Concept Bottleneck Models (CBMs) are interpretable learning architectures that factor predictions through intermediate, ideally human-understandable concepts, enabling explicit and inspectable reasoning. Although CBM research has gained substantial momentum in recent years, this growth has also revealed numerous open challenges and a fragmented set of methodological choices. In this work, we systematically review the CBM literature, identify previously unidentified core components and challenges, and propose a unified taxonomy. Based on this taxonomy, we provide a detailed categorization of existing works. We hereby discuss current challenges for the CBM paradigm and outline important directions to extend it beyond its current scope. Overall, this survey aims to consolidate the CBM landscape, clarify open issues, and provide guidance for developing future models.
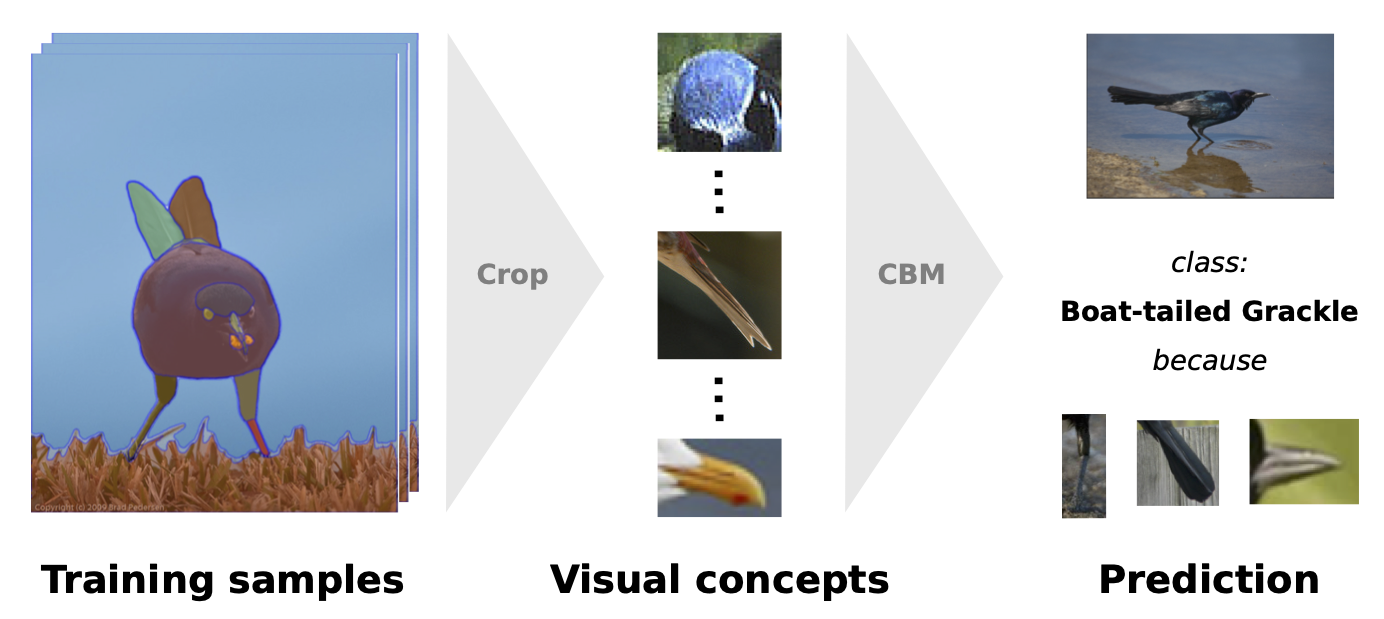
DCBM: Data-Efficient Visual Concept Bottleneck Models
Katharina Prasse*, Patrick Knab*, Sascha Marton, Christian Bartelt, Margret Keuper (* equal contribution)
International Conference on Computer Vision (ICCV) @ eXCV Workshop 2025
Concept Bottleneck Models (CBMs) enhance the interpretability of neural networks by basing predictions on human-understandable concepts. However, current CBMs typically rely on concept sets extracted from large language models or extensive image corpora, limiting their effectiveness in data-sparse scenarios. We propose Dataefficient CBMs (DCBMs), which reduce the need for large sample sizes during concept generation while preserving interpretability. DCBMs define concepts as image regions detected by segmentation or detection foundation models, allowing each image to generate multiple concepts across different granularities. This removes reliance on textual descriptions and large-scale pre-training, making DCBMs applicable for fine-grained classification and out-of-distribution tasks. Attribution analysis using Grad-CAM demonstrates that DCBMs deliver visual concepts that can be localized in test images. By leveraging dataset-specific concepts instead of predefined ones, DCBMs enhance adaptability to new domains.
DCBM: Data-Efficient Visual Concept Bottleneck Models
Katharina Prasse*, Patrick Knab*, Sascha Marton, Christian Bartelt, Margret Keuper (* equal contribution)
International Conference on Computer Vision (ICCV) @ eXCV Workshop 2025
Abstract
Concept Bottleneck Models (CBMs) enhance the interpretability of neural networks by basing predictions on human-understandable concepts. However, current CBMs typically rely on concept sets extracted from large language models or extensive image corpora, limiting their effectiveness in data-sparse scenarios. We propose Dataefficient CBMs (DCBMs), which reduce the need for large sample sizes during concept generation while preserving interpretability. DCBMs define concepts as image regions detected by segmentation or detection foundation models, allowing each image to generate multiple concepts across different granularities. This removes reliance on textual descriptions and large-scale pre-training, making DCBMs applicable for fine-grained classification and out-of-distribution tasks. Attribution analysis using Grad-CAM demonstrates that DCBMs deliver visual concepts that can be localized in test images. By leveraging dataset-specific concepts instead of predefined ones, DCBMs enhance adaptability to new domains.
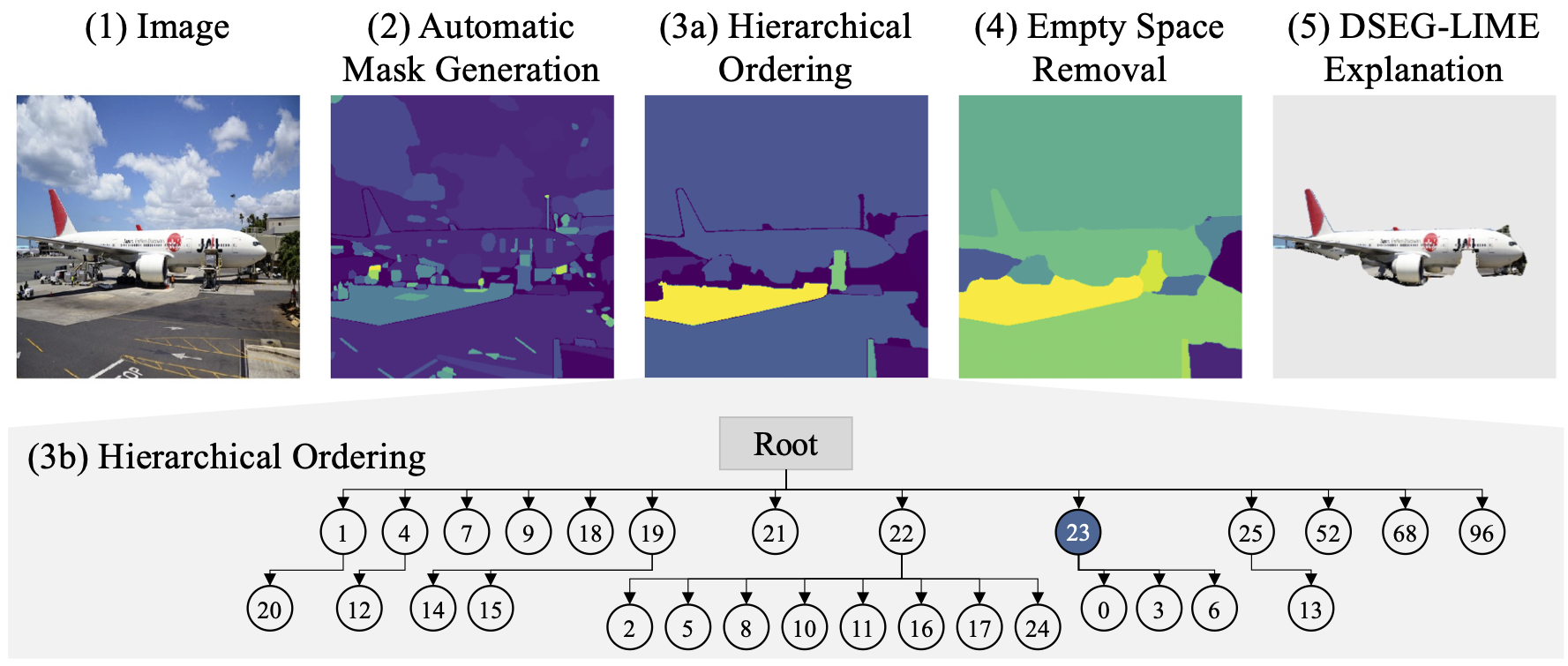
Beyond Pixels: Enhancing LIME with Hierarchical Features and Segmentation Foundation Models
Patrick Knab, Sascha Marton, Christian Bartelt
28th European Conference on Artificial Intelligence (ECAI) 2025
LIME (Local Interpretable Model-agnostic Explanations) is a popular XAI framework for unraveling decision-making processes in vision machine-learning models. The technique utilizes image segmentation methods to identify fixed regions for calculating feature importance scores as explanations. Therefore, poor segmentation can weaken the explanation and reduce the importance of segments, ultimately affecting the overall clarity of interpretation. To address these challenges, we introduce the DSEG-LIME (Data-Driven Segmentation LIME) framework, featuring: i) a data-driven segmentation for human-recognized feature generation by foundation model integration, and ii) a user-steered granularity in the hierarchical segmentation procedure through composition. Our findings demonstrate that DSEG outperforms on several XAI metrics on pre-trained ImageNet models and improves the alignment of explanations with human-recognized concepts. The code is available under: https://github.com/patrick-knab/DSEG-LIME
Beyond Pixels: Enhancing LIME with Hierarchical Features and Segmentation Foundation Models
Patrick Knab, Sascha Marton, Christian Bartelt
28th European Conference on Artificial Intelligence (ECAI) 2025
Abstract
LIME (Local Interpretable Model-agnostic Explanations) is a popular XAI framework for unraveling decision-making processes in vision machine-learning models. The technique utilizes image segmentation methods to identify fixed regions for calculating feature importance scores as explanations. Therefore, poor segmentation can weaken the explanation and reduce the importance of segments, ultimately affecting the overall clarity of interpretation. To address these challenges, we introduce the DSEG-LIME (Data-Driven Segmentation LIME) framework, featuring: i) a data-driven segmentation for human-recognized feature generation by foundation model integration, and ii) a user-steered granularity in the hierarchical segmentation procedure through composition. Our findings demonstrate that DSEG outperforms on several XAI metrics on pre-trained ImageNet models and improves the alignment of explanations with human-recognized concepts. The code is available under: https://github.com/patrick-knab/DSEG-LIME
DCBM: Data-Efficient Visual Concept Bottleneck Models
Katharina Prasse*, Patrick Knab*, Sascha Marton, Christian Bartelt, Margret Keuper (* equal contribution)
International Conference on Machine Learning (ICML) 2025
Concept Bottleneck Models (CBMs) enhance the interpretability of neural networks by basing predictions on human-understandable concepts. However, current CBMs typically rely on concept sets extracted from large language models or extensive image corpora, limiting their effectiveness in data-sparse scenarios. We propose Dataefficient CBMs (DCBMs), which reduce the need for large sample sizes during concept generation while preserving interpretability. DCBMs define concepts as image regions detected by segmentation or detection foundation models, allowing each image to generate multiple concepts across different granularities. This removes reliance on textual descriptions and large-scale pre-training, making DCBMs applicable for fine-grained classification and out-of-distribution tasks. Attribution analysis using Grad-CAM demonstrates that DCBMs deliver visual concepts that can be localized in test images. By leveraging dataset-specific concepts instead of predefined ones, DCBMs enhance adaptability to new domains.
DCBM: Data-Efficient Visual Concept Bottleneck Models
Katharina Prasse*, Patrick Knab*, Sascha Marton, Christian Bartelt, Margret Keuper (* equal contribution)
International Conference on Machine Learning (ICML) 2025
Abstract
Concept Bottleneck Models (CBMs) enhance the interpretability of neural networks by basing predictions on human-understandable concepts. However, current CBMs typically rely on concept sets extracted from large language models or extensive image corpora, limiting their effectiveness in data-sparse scenarios. We propose Dataefficient CBMs (DCBMs), which reduce the need for large sample sizes during concept generation while preserving interpretability. DCBMs define concepts as image regions detected by segmentation or detection foundation models, allowing each image to generate multiple concepts across different granularities. This removes reliance on textual descriptions and large-scale pre-training, making DCBMs applicable for fine-grained classification and out-of-distribution tasks. Attribution analysis using Grad-CAM demonstrates that DCBMs deliver visual concepts that can be localized in test images. By leveraging dataset-specific concepts instead of predefined ones, DCBMs enhance adaptability to new domains.
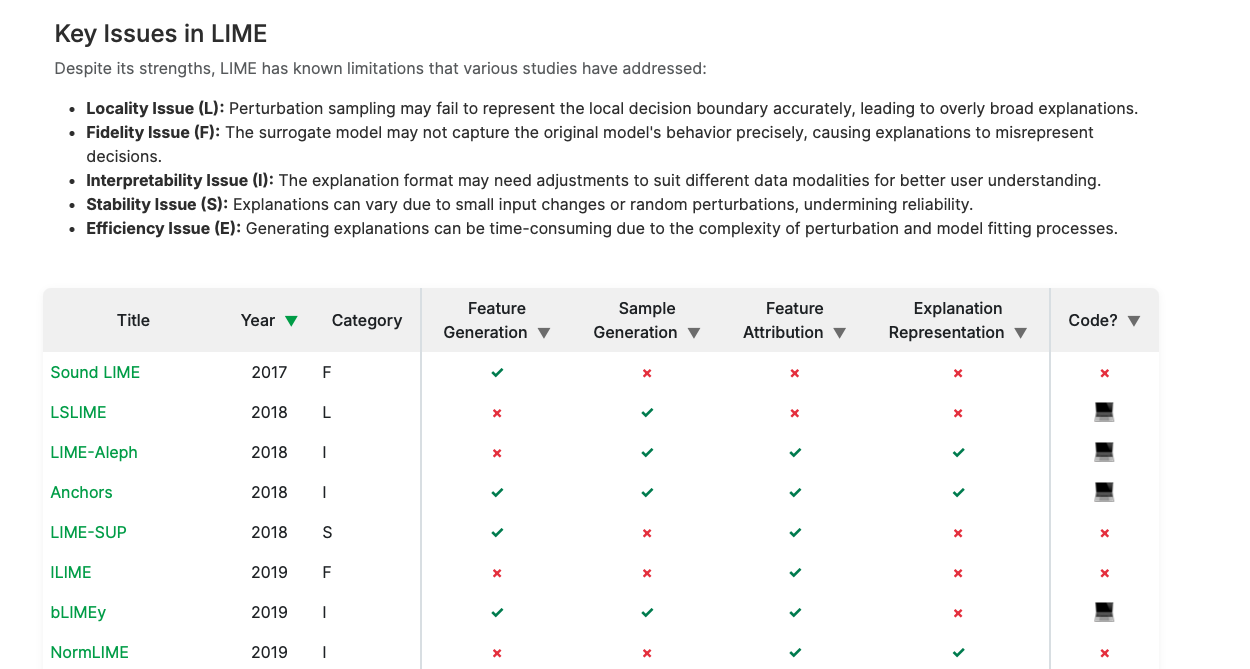
Which LIME should I trust? Concepts, Challenges and Solutions
Patrick Knab, Sascha Marton, Udo Schlegel, Christian Bartelt
The World Conference on eXplainable Artificial Intelligence (XAI) 2025
As neural networks become dominant in essential systems, Explainable Artificial Intelligence (XAI) plays a crucial role in fostering trust and detecting potential misbehavior of opaque models. LIME (Local Interpretable Model-agnostic Explanations) is among the most prominent model-agnostic approaches, generating explanations by approximating the behavior of black-box models around specific instances. Despite its popularity, LIME faces challenges related to fidelity, stability, and applicability to domain-specific problems. Numerous adaptations and enhancements have been proposed to address these issues, but the growing number of developments can be overwhelming, complicating efforts to navigate LIME-related research. To the best of our knowledge, this is the first survey to comprehensively explore and collect LIME's foundational concepts and known limitations. We categorize and compare its various enhancements, offering a structured taxonomy based on intermediate steps and key issues. Our analysis provides a holistic overview of advancements in LIME, guiding future research and helping practitioners identify suitable approaches. Additionally, we provide a continuously updated interactive website (https://patrick-knab.github.io/which-lime-to-trust/), offering a concise and accessible overview of the survey.
Which LIME should I trust? Concepts, Challenges and Solutions
Patrick Knab, Sascha Marton, Udo Schlegel, Christian Bartelt
The World Conference on eXplainable Artificial Intelligence (XAI) 2025
Abstract
As neural networks become dominant in essential systems, Explainable Artificial Intelligence (XAI) plays a crucial role in fostering trust and detecting potential misbehavior of opaque models. LIME (Local Interpretable Model-agnostic Explanations) is among the most prominent model-agnostic approaches, generating explanations by approximating the behavior of black-box models around specific instances. Despite its popularity, LIME faces challenges related to fidelity, stability, and applicability to domain-specific problems. Numerous adaptations and enhancements have been proposed to address these issues, but the growing number of developments can be overwhelming, complicating efforts to navigate LIME-related research. To the best of our knowledge, this is the first survey to comprehensively explore and collect LIME's foundational concepts and known limitations. We categorize and compare its various enhancements, offering a structured taxonomy based on intermediate steps and key issues. Our analysis provides a holistic overview of advancements in LIME, guiding future research and helping practitioners identify suitable approaches. Additionally, we provide a continuously updated interactive website (https://patrick-knab.github.io/which-lime-to-trust/), offering a concise and accessible overview of the survey.
DCBM: Data-Efficient Visual Concept Bottleneck Models
Katharina Prasse*, Patrick Knab*, Sascha Marton, Christian Bartelt, Margret Keuper (* equal contribution)
Conference on Computer Vision and Pattern Recognition (CVPR) @ XAI4CV Workshop 2025
Concept Bottleneck Models (CBMs) enhance the interpretability of neural networks by basing predictions on human-understandable concepts. However, current CBMs typically rely on concept sets extracted from large language models or extensive image corpora, limiting their effectiveness in data-sparse scenarios. We propose Dataefficient CBMs (DCBMs), which reduce the need for large sample sizes during concept generation while preserving interpretability. DCBMs define concepts as image regions detected by segmentation or detection foundation models, allowing each image to generate multiple concepts across different granularities. This removes reliance on textual descriptions and large-scale pre-training, making DCBMs applicable for fine-grained classification and out-of-distribution tasks. Attribution analysis using Grad-CAM demonstrates that DCBMs deliver visual concepts that can be localized in test images. By leveraging dataset-specific concepts instead of predefined ones, DCBMs enhance adaptability to new domains.
DCBM: Data-Efficient Visual Concept Bottleneck Models
Katharina Prasse*, Patrick Knab*, Sascha Marton, Christian Bartelt, Margret Keuper (* equal contribution)
Conference on Computer Vision and Pattern Recognition (CVPR) @ XAI4CV Workshop 2025
Abstract
Concept Bottleneck Models (CBMs) enhance the interpretability of neural networks by basing predictions on human-understandable concepts. However, current CBMs typically rely on concept sets extracted from large language models or extensive image corpora, limiting their effectiveness in data-sparse scenarios. We propose Dataefficient CBMs (DCBMs), which reduce the need for large sample sizes during concept generation while preserving interpretability. DCBMs define concepts as image regions detected by segmentation or detection foundation models, allowing each image to generate multiple concepts across different granularities. This removes reliance on textual descriptions and large-scale pre-training, making DCBMs applicable for fine-grained classification and out-of-distribution tasks. Attribution analysis using Grad-CAM demonstrates that DCBMs deliver visual concepts that can be localized in test images. By leveraging dataset-specific concepts instead of predefined ones, DCBMs enhance adaptability to new domains.
Beyond Pixels: Enhancing LIME with Hierarchical Features and Segmentation Foundation Models
Patrick Knab, Sascha Marton, Christian Bartelt
International Conference on Learning Representations (ICLR) @ FM-Wild Workshop 2025
LIME (Local Interpretable Model-agnostic Explanations) is a popular Interpretable AI framework for unraveling decision-making processes in vision machine-learning models. The technique utilizes image segmentation methods to identify fixed regions for calculating feature importance scores as explanations. Therefore, poor segmentation can weaken the explanation and reduce the importance of segments, ultimately affecting the overall clarity of interpretation. To address these challenges, we introduce the DSEG-LIME (Data-Driven Segmentation LIME) framework, featuring: i) a data-driven segmentation for human-recognized feature generation by foundation model integration, and ii) a user-steered granularity in the hierarchical segmentation procedure through composition. Our findings demonstrate that DSEG outperforms on several Interpretable AI metrics on pre-trained ImageNet models and improves the alignment of explanations with human-recognized concepts. The code is available under: https://github.com/patrick-knab/DSEG-LIME
Beyond Pixels: Enhancing LIME with Hierarchical Features and Segmentation Foundation Models
Patrick Knab, Sascha Marton, Christian Bartelt
International Conference on Learning Representations (ICLR) @ FM-Wild Workshop 2025
Abstract
LIME (Local Interpretable Model-agnostic Explanations) is a popular Interpretable AI framework for unraveling decision-making processes in vision machine-learning models. The technique utilizes image segmentation methods to identify fixed regions for calculating feature importance scores as explanations. Therefore, poor segmentation can weaken the explanation and reduce the importance of segments, ultimately affecting the overall clarity of interpretation. To address these challenges, we introduce the DSEG-LIME (Data-Driven Segmentation LIME) framework, featuring: i) a data-driven segmentation for human-recognized feature generation by foundation model integration, and ii) a user-steered granularity in the hierarchical segmentation procedure through composition. Our findings demonstrate that DSEG outperforms on several Interpretable AI metrics on pre-trained ImageNet models and improves the alignment of explanations with human-recognized concepts. The code is available under: https://github.com/patrick-knab/DSEG-LIME